
Übersicht: [anzeigen]
Einführung: Das Betriebssystem Linux
Linux ist ein freies Multiplattform-Mehrbenutzer-Betriebssystem, das den Linux-Kernel enthält. Im praktischen Einsatz werden meist sogenannte Linux-Distributionen genutzt, in denen der Linux-Kernel und verschiedene Software zu einem fertigen Paket zusammengestellt sind.
Aufbau des Betriebssystems
Das zentrale Kernstück des Betriebssystems, der Linux-Kernel (meist nur Kernel genannt) bildet eine Trennschicht zwischen Hardware und Anwenderprogrammen. Das heißt, wenn ein Programm auf ein Stück Hardware zugreifen will, so kann es niemals direkt darauf zugreifen, sondern nur über das Betriebssystem.
Dazu bedient sich das Programm der Systemaufrufe. Über den Systemaufruf teilt das Anwenderprogramm dem Betriebssystem mit, dass es etwas zu tun gibt. Will etwa ein Programm eine Zeile Text auf dem Bildschirm ausgeben, so wird ein Systemaufruf gestartet, dem der Text übergeben wird. Das Betriebssystem erst schreibt ihn auf den Bildschirm.
Auf der anderen Seite muss das Betriebssystem die Möglichkeit haben, mit den einzelnen Hardware-Komponenten zu sprechen. Mittels seiner Treiberschnittstelle spricht es spezielle Geräte-Treiber an. Erst die Treiber kommunizieren dann direkt mit den Geräten.
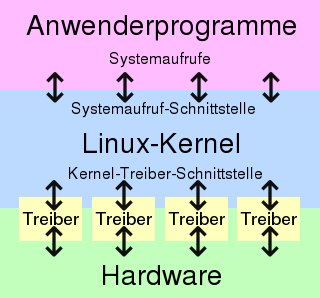
Zu den Anwenderprogrammen zählen alle von uns gestarteten Programme (Videoplayer, Webbrowser ...), wie auch die grafische Oberfäche des Betriebssystems, das Desktop-Environment. Letzteres ist nicht ein Programm, sondern eine Sammlung von Programmen, die zusammen die gewohnten Funktionalitäten beisteuern.
Ein ganz spezielles Anwenderprogramm ist die Shell - die "Benutzeroberfläche". Es existieren viele verschiedene Shells - wir werden hier mit der Bash (Bourne again shell) arbeiten. Diese ist die Standardshell auf Linuxsystemen. Alle Shells stellen dem Benutzer eine Kommandozeile zur Verfügung, mit der Befehle eingegeben werden können, die direkt als Systemaufrufe an das Betriebssystem weitergeleitet werden.
Linux ist ein Multitasking-Betriebssystem: das heißt, es können mehrere Prozesse - so nennt man Programme, sobald sie in den Speicher geladen sind und laufen - gleichzeitig laufen. Das bedingt, dass das System die verfügbare Rechenzeit des Prozessors in kleine Zeitscheiben aufteilt (im Millisekundenbereich), die dann den jeweiligen Prozessen zur Verfügung stehen. Diese Aufgabe übernimmt eine übergeordnete Instanz - der Scheduler. Dieser verwaltet die Zuteilung der Zeitscheiben an die verschiedenen Prozesse.
Daher kann kein Prozess die ganze Rechenleistung für sich beanspruchen und auch ein "hängender" Prozess kann nicht das ganze System lahmlegen.
Die Benutzer
Linux ist auch ein Multiuser-System, das heißt, es können mehrere Benutzer an verschieden Terminals auf dem selben Rechner arbeiten. Dazu ist es natürlich notwendig, dass jeder Benutzer eindeutig identifiziert ist. Die User (engl., Benutzer) werden zwar mit ihren Namen verwaltet, intern arbeitet ein Unix-System aber mit Usernummern. Jeder Benutzer hat also eine Nummer welche UserID oder kurz UID genannt wird.
Jeder Benutzer ist auch Mitglied mindestens einer Gruppe. Es kann beliebig viele Gruppen in einem System geben und auch sie haben intern Nummern (GroupID oder GID). Im Prinzip sind Gruppen nur eine Möglichkeit, noch detailiertere Einstellungsmöglichkeiten zu haben, wer was darf.
Eine spezielle Rolle hat der Benutzer mit der UserID 0 - er ist Root (engl., Wurzel). Root steht außerhalb aller Sicherheitseinrichtungen des Systems - kurz - er darf alles. Er kann mit einem Befehl das ganze System zerstören, er kann die Arbeit von Wochen und Monaten löschen usw. Aus diesem Grund meldet sich auch der Systemverwalter im Normalfall als normaler Benutzer an - zum Root-Benutzer wird er nur dann, wenn er Systemverwaltungsarbeiten abwickelt, die diese Identität benötigen.
Die Dateien
Datei- und Verzeichnisnamen können bis zu 255 Zeichen lang sein. Dabei wird in jedem Fall zwischen Groß- und Kleinschreibung unterschieden. Die Dateinamen
DATEI
datei
Datei
bezeichnen drei unterschiedliche Dateien. Ein Dateiname darf beliebig viele Punkte enthalten, also zum Beispiel auch Datei.Teil.1.txt. Ein Punkt gilt als normales Zeichen in einem Dateinamen. Dateien, die mit Punkt beginnen, gelten als versteckt und werden normalerweise nicht angezeigt - zum Beispiel .datei. Das Zeichen zum Trennen von Verzeichnis- und Dateinamen ist der Slash ("/") statt dem Backslash ("\") bei Windows.
Es gibt verschiedene Dateiarten:
(in Klammer die offizielle Darstellung, wie sie symbolisiert werden)
-
Normale Dateien (-)
-
Verzeichnisse (d)
-
Symbolische Links (l)
-
Blockorientierte Geräte (b)
-
Zeichenorientierte Geräte (c)
-
Named Pipes (p)
Wir sehen hier schon, dass auch Verszeichnisse bloß eine bestimmte Dateiart sind. Eine spezielle nämlich, in der andere Dateien aufgelistet sind. Mit einem Dateibrowser (von Windows kennen wir "Explorer", bei Apple den "Finder") sehen wir uns immer nur genau diese Verzeichnisse an, sofern wir nicht mittels verschiedener Plugins die Dateien selbst auswerten und Textdokumente, Bilder anzeigen oder Videos und Musik wiedergeben.
In einem Unix-Dateisystem hat jede einzelne Datei jeweils einen Eigentümer und eine Gruppenzugehörigkeit. Neben diesen beiden Angaben besitzt jede Datei noch einen Satz Attribute, die bestimmen, wer die Datei wie benutzen darf. Diese Attribute werden dargestellt als "rwx". Dabei steht r für lesen (read), w für schreiben (write) und x für ausführen (execute).
Das Dateisystem
Das Dateisystem ist die Ablageorganisation auf einem Datenträger eines Computers. Um die Funktionsweise zu verstehen, betrachten wir einen Datenträger, die Festplatte, näher:
Die Festplatte besteht aus mehreren Scheiben mit einer magnetisierbaren Oberfläche, auf die die Schreibköpfe unsere Daten als Einsen (ein) und Nullen (aus) abspeichern. Um diese aber vernünftig adressieren zu können, benutzen wir Dateisysteme. Ein solches teilt die Festplatte (eigentlich die "Partition", denn die Festplatte wird häufig in mehrere Partitionen aufgeteilt, die dann unabhängig formatiert werden können) in kleine Einheiten, die "Blöcke", welche aus Performancegründen häufig noch zu "Clustern" zusammengefasst werden.
Der Block (oder Cluster) ist dann die kleinste Einheit, in die eine Datei geschrieben wird, jede Datei benötigt dadurch immer diesen Speicherplatz (oder ein vielfaches) auf der Festplatte.
Von Windows kennen wir NTFS und FAT32, bzw. Apple-Benutzer werden schon von HFS+ gehört haben. Unter Linux werden meist ext2, ext3 oder ext4 (Second, Third bzw. Fourth Extented File System) verwendet. "ext3" unterscheidet sich von "ext2" nur dadurch, dass zusätzlich ein "Journal" geschrieben wird, welches bei Systemabstürzen eine zuverlässige Wiederherstellung möglich macht. "ext4" ist eine performantere Weiterentwicklung von "ext3" und heute Standard. Daneben gibt es gelegentlich noch ReiserFS, XFS oder JFS, aber die Wahl des Dateisystems bestimmt tatsächlich immer das Abwägen zwischen höherer Sicherheit und schnellerer Schreibgeschwindigkeit - mit oder ohne Journal.
Die Verzeichnisstruktur
Während unter Windows jedes logische oder physikalische Laufwerk (Festplattenpartitionen oder Geräte wie CD-Laufwerk) seinen eigenen Dateibaum, ausgehend vom Laufwerksbuchstaben hat, gibt es unter UNIX-Systemen nur einen Dateibaum, ausgehend vom Wurzelverzeichnis (am Anfang einer bestimmten Festplattenpartition), in den die anderen Laufwerke an beliebiger Stelle eingehängt werden können. Sie sind sozusagen nur Äste des einen Dateibaums.
Nun wollen wir diesen Dateibaum einmal näher betrachten. Linux hat, wie jedes Unix-System, einen sehr genau vorgeschriebenen Dateibaum. Die wichtigsten Verzeichnisse heißen immer gleich, so dass es beinahe egal ist, mit welchem Unix wir arbeiten. Wir werden uns überall zurechtfinden.
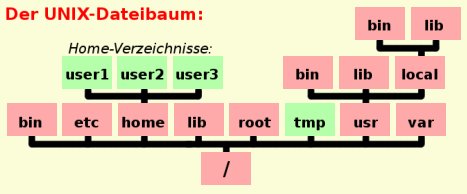
Das Wurzelverzeichnis /
Wie bereits gesagt hat Linux nur einen Dateibaum. Eine Partition (bzw. ein Laufwerk) ist also die sogenannte root-partition (Wurzelpartition). Alle anderen Partitionen und Laufwerke (auch CD-Laufwerk, USB-Stick, externe Festplatte) werden an beliebigen Stellen in den Wurzeldateibaum "montiert" (mounted).
In diesem Wurzelverzeichnis darf neben den Verzeichnissen nur eine einzige normale Datei liegen, nämlich der Kernel. Aber auch dies ist auf modernen Systemen nicht mehr der Fall, da der Kernel in das Verzeichnis /boot ausgelagert ist. Im Wurzelverzeichnis befindet sich stattdessen ein symbolischer Link auf den Kernel.
Das Verzeichnis /bin
Hier liegen Binaries, also binäre Programme, jedoch nur jene, die für die wichtigsten Arbeiten am System benötigt werden. Alle User haben in diesem Verzeichnis Lesezugriff.
Das Verzeichnis /boot
Hier liegt der Linux-Kernel und alle Dateien, die er zum Starten benötigt. Nur der root-Benutzer hat auf dieses Verzeichnis Zugriff.
Das Verzeichnis /dev
Hier liegen die Gerätedateien. Gerätedateien sind Schnittstellen zum Kernel, die ein bestimmtes Gerät bezeichnen. Unter Unix ist fast jedes Stück Hardware mit einer solchen Gerätedatei ansprechbar. Wichtig ist, dass diese Dateien keinen physikalischen Platz auf der Platte brauchen.
Das Verzeichnis /etc
Hier sind alle systemweit gültigen Konfigurationsdateien (Netzwerk, Bootmanager, Sytemstartscripts, ...) abgelegt, sowie die Dateien für die Benutzerverwaltung (z.B. "passwd" und "shadow" mit den Benutzern und ihren Passwörtern).
Viele Prozesse müssen diese Dateien lesen können, um bestimmte Informationen zu bekommen. Daher muss das Verzeichnis für alle User lesbar sein.
Das Verzeichnis /home
Jeder User, den das System kennt, hat ein eigenes Verzeichnis, das in der Regel den gleichen Namen trägt, wie der User selbst. Wir nennen solche Verzeichnisse die "Home-Verzeichnisse" der Benutzer. Sie liegen alle (außer dem vom Systemverwalter "root") im Verzeichnis /home. Nach dem Einloggen (Anmelden beim System mit Username und Passwort) befinden sich alle User immer in ihrem Home-Verzeichnis.
Innerhalb des eigenen Home-Verzeichnisses darf ein User in der Regel alles machen - auch Dateien anlegen, löschen und verändern. Außerhalb seines Verzeichnisses hat ein normaler Benutzer meist nur Leserechte - verändern, anlegen oder löschen darf er dort nicht.
Das Verzeichnis /lib
Hier liegen die Libraries, die Systembibliotheken von Unix. Dabei handelt es sich sowohl um statische Bibliotheken für das System, als auch um dynamische, die in etwa funktionieren wie die DLLs von Windows.
Die Verzeichnisse /mnt und /media
In diesen Verzeichnissen finden sich Unterverzeichnisse, die zunächst eigentlich leer sind. Sie dienen dazu, gemountete Laufwerke und Geräte einzubinden.
Ein Beispiel: in /mnt/datenarchiv könnte eine zweite, im System verbaute Festplatte eingehängt sein und unter /media/cdrom0 finden wir sehr wahrscheinlich unser (erstes) CD/DVD-Laufwerk.
Beide Verzeichnisse erfüllen den gleichen Zweck und die Verwendung ist uneinheitlich, aber meist werden in /media Wechchseldatenträger und alle erst nach Systemstart vom Benutzer eingehänten Dateisysteme (wie externe Festplatten und USB-Sticks) verwaltet.
Das Verzeichnis /proc
Auch dieses Verzeichnis benötigt keinen Platz auf der Platte, es enthält Informationen, die das laufende System ständig auffrischt. Es sind eigentlich keine Dateien und Verzeichnisse, die hier liegen, sondern Informationen des Kernels.
Das Verzeichnis /root
Dies ist das Home-Verzeichnis des Systemverwalters "root". Warum ist dieses Verzeichnis aber nicht im Verzeichnis /home? Ganz einfach: /home ist häufig als eigene Partition implementiert. Diese Partition wird aber erst während des Systemstarts eingehängt (mounted). Falls es zu einem Fehler kommen sollte, muss der Systemverwalter das System starten können ohne alle Partitionen einzuhängen. Es muss also auf dem Wurzelverzeichnis bereits ein arbeitsfähiges System bereitstehen. Zu einem arbeitsfähigen System gehört aber unbedingt das Home-Verzeichnis. Daher liegt das Home-Verzeichnis von "root" direkt auf der Wurzel und in der selben Partition.
In frühen Unix-Systemen war das Home-Verzeichnis von "root" tatsächlich das Wurzelverzeichnis (engl. root directory), aber da sich in einem Home-Verzeichnis immer eine Menge Dateien ansammeln, wurde das zu unübersichtlich und sein Home-Verzeichnis ins Verzeichnis /root ausgelagert.
Das Verzeichnis /sbin
Wie schon in /bin liegen auch hier Binaries, allerdings solche, die hauptsächlich der Systemverwalter benutzt - "System-Binaries", sozusagen.
Das Verzeichnis /tmp
In diesem Verzeichnis werden, wie schon der Name vermuten lässt, temporäre Dateien abgelegt, die nach Verwendung nicht mehr benötigt werden. Alle Benutzer müssen hier schreiben können, aber es ist kein guter Ort, um seine Daten sicher zu verwahren. Der gesamte Inhalt wird nämlich normalerweise beim Neustart des Systems gelöscht.
Das Verzeichnis /usr
Dieses Verzeichnis enthält alle wichtigen Programme, die das System anbietet. "usr" steht dabei nicht, wie irrtümlich häufig angenommen für "User", sondern für "Unix System Resources".
Als Unterverzeichnisse finden wir hier analog zur Wurzel /usr/bin, /usr/lib und /usr/sbin und ihre Bedeutung entspricht jeweils denen des Wurzelverzeichnisses.
Einige weitere wichtige Unterverzeichnisse wollen wir noch näher betrachten:
/usr/local dient der Trennung von distributionseigenen und fremden, zusätzlich installierten Programmen. Unter /usr/local finden wir nochmals die gleichen Verzeichnisse wie im Verzeichnis /usr selbst. Selbst kompilierte Programme sollten immer in /usr/local installiert werden und nie direkt in /usr und die Konfigurationsscripts der Programme sehen dies meist auch als Default vor.
/usr/share beinhaltet architekturunabhängige Daten, die verschiedene Programme zum Betrieb benötigen und die nicht verändert werden.
/usr/src enthält die Quelltexte für alle Programme des Standardsystems.
Das Verzeichnis /var
Dieses Verzeichnis beinhaltet Daten, die von Programmen häufig neu geschrieben werden müssen. Ursprünglich waren diese Daten auch unter /usr zu finden, aber der Wunsch /usr auch schreibgeschützt mounten zu können machte eine Trennung notwendig. Hier werden auf einem Mailserver Mails zwischengelagert (/var/spool) und alle Programme schreiben hierher ihre Log-Dateien (/var/log).
Wir werden auch noch einige andere Verzeichnisse und Unterverzeichnisse finden, die teilweise leer sind oder nur symbolische Links in andere Verzeichnisse enthalten und häufig aus Kompatibilitätsgründen existieren. Ein Verzeichnis sei vielleicht noch erwähnt:
Das Verzeichnis /opt
Dieses Verzeichnis ist eine Linux-Erfindung. Nachdem immer mehr große Programmpakete installiert wurden, gab es die Überlegung, diese nicht mehr in das Verzeichnis /usr zu packen, sondern ein eigenes Verzeichnis dafür zu schaffen. Tatsächlich nutzen nur wenige Programme von sich aus diese Möglichkeit und auf vielen Systemen bleibt dieses Verzeichnis leer.
Die Linux-Distributionen
Wie schon besprochen besteht ein Linux-Betriebssystem aus dem Linux-Kernel und einer großen Anzahl verschiedener Anwenderprogramme. Tatsächlich gibt es ein Projekt, das eine Anleitung bietet, wie man aus den Kernelquellen und selbst selektierten Programmen ein komplettes, maßgeschneidertes Betriebssystem bauen kann. Das Projekt nennt sich "Linux From Scratch" oder "LFS" (www.linuxfromscratch.org) und ich kann jedem, der etwas Zeit übrig hat, nur empfehlen, dies selbst einmal zu probieren.
Man erhält eine ultrakompaktes, ultraschnelles Betriebssystem und kann sagen, "das ist mein eigenes reinrassiges Linux-System". Aber was kommt dann?
Man braucht schon einige Zeit bis alle Programme, die so benötigt werden, kompiliert und konfiguriert sind und dann müssen diese auch noch laufend aktualisiert werden. Sicherheitsupdates müssen selbst organisiert und kompiliert werden. Mit all der Administrationsarbeit kommt man zu sonst nichts mehr.
Um das zu vermeiden, gibt es Linux-Distributionen. Diese bieten nicht nur einen fertigen Satz von notwendigen Programmen, sondern auch die regelmäßige Versorgung mit Updates an. Die aus meiner Sicht wichtigsten Distributionen sollen hier aufgeführt werden:
Debian
"Debian" (www.debian.org) ist eine nicht-kommerzielle Distribution und das "Debian-Projekt" ist nach der "Debian-Verfassung" geregelt, die eine demokratische Organisationsstruktur vorsieht. Darüberhinaus ist das Projekt über den "Debian Social Contract" zu völlig freier Software verpflichtet. Mit einigen 1000 Mitarbeitern ist Debian der Gigant unter den Linux-Systemen.
Da bei Debian eine "stabile Version" immer eine wirklich stabile Version ist, sind die Entwicklungszeiten relativ lang und böse Zungen behaupten auch, dass die stabile Version schon bei Erscheinen veraltet ist.
Allerdings bietet Debian auch immer schon die zukünftigen Versionen an und so gibt es mehrere Zweige, aus denen man sich bedienen kann:
stable - wirklich stabile Version, die auch für den kommerziellen Serverbetrieb geeignet ist!
testing - die zukünftige stable-Version. Ab einem gewissen Entwicklungsstand wird die Distribution "eingefroren" (engl. "frozen") - d.h. es werden keine neueren Versionen von Programmen mehr aufgenommen, sondern nur noch an der Fehlerbeseitigung bei den vorhandenen gearbeitet. Dies entspricht ungefähr dem Zustand, bei dem andere Distributoren ihre "stabilen" Versionen veröffentlichen.
Da ich schon mehrmals eine testing-Version ab dem Anfangsstadium benutzt habe, glaube ich sogar sagen zu können, dass testing nie so instabil ist, wie manche andere Distribution im "ausgereiften" Zustand. Für den Desktopbetrieb kann ich ein eingefrorenes testing jedenfalls empfehlen.
unstable - ist der erste Anlaufpunkt für neue Versionen von Paketen und Programmen, bevor sie in testing integriert werden. Man installiert sich mit unstable das neueste vom neuen, muss aber wissen, dass das nicht immer stabil ist.
experimental - ist kein vollständiger Zweig, denn es dient nur dazu, Programme und deren Funktionen zu testen, die sonst das ganze System gefährden würden. Es enthält immer nur die gerade getesteten, bzw. die von diesen benötigten Programmpakete.
Diese Zweige haben auch immer Codenamen und sind, einer Vorliebe der frühen Entwickler folgend, immer nach Figuren aus dem Film "Toy Story" benannt. So heißt im Moment die stable-Version "Stretch" und "Buster" ist testing. unstable ist immer "Sid", der Junge von nebenan, der die Spielsachen zerstört, aber es lässt sich auch als Abkürzung für "still in development" (noch in Entwicklung) deuten.
Und wer einen dieser Zweige installiert hat, kann auf eine unüberschaubare Vielzahl an Programmen zurückgreifen, auf Wunsch (und auf eigene Gefahr) auch aus den anderen Zweigen. Für Anfänger ist es wohl nur bedingt zu empfehlen, obwohl sich in den letzten Jahren sehr viel in Sachen Benutzerführung getan hat. Auch steht ein deutschsprachiges Forum (debianforum.de) zur Verfügung, wo man Hilfe bekommt und wo auch dumme Fragen gestellt werden dürfen. Für ambitionierte Linux-EinsteigerInnen, die sich auch mit den Möglichkeiten ihres Betriebssystems auseinandersetzen wollen, könnte es sogar die beste Distribution sein.
Fedora
Das nicht-kommerzielle "Fedora" (getfedora.org) ist der Nachfolger des traditionsreichen, kommerziellen "Red Hat Linux", welches nicht mehr selbständig weiterentwickelt wird. Statt dessen verkauft die Firma Red Hat, das auf Fedora basierende "Red Hat Enterprise Linux".
Fedora ist eine sehr innovative Distribution und vor allem in den USA sehr beliebt. Es werden nur völlig unter freier Lizenz stehende Inhalte akzeptiert, weshalb nach der Installation zum Beispiel keine MP3-unterstützenden Programme zu finden sind. Für Anfänger gibt es bessere Distributionen.
Gentoo Linux
Das nicht-kommerzielle "Gentoo Linux" (www.gentoo.de) ist eine quellbasierte Linux-Metadistribution - das heißt, alle Programme, inklusive des Kernels, werden selbst kompiliert. Das klingt sehr anstrengend, ist es aber gar nicht so, da die Distribution geeignete Werkzeuge zur Verfügung stellt, mit denen dies einfachst möglich gelingt. Auch sorgt eine große, sehr aktive "Community" bei jedem Problem für Rat und Hilfe. Dennoch ist sie für Linux-Neulinge wohl nicht empfehlenswert.
OpenSUSE
"openSUSE" (www.opensuse.org) ist die zweitbeliebteste Distribution am Heim-PC. Die nicht-kommerzielle Variante der von Novell aufgekauften kommerziellen SUSE-Distribution (heute "SUSE Linux Enterprise") glänzt mit einem universellen Konfigurationswerkzeug. Sie gilt als anfängerfreundlich. Die neueste Versionsnummer 42.1 bezieht sich übrigens auf die Antwort auf die Frage "nach dem Leben, dem Universum und dem ganzen Rest" aus Douglas Adam's "Per Anhalter durch die Galaxis". Schon 1996 hatte die Version 4.2 diesen Bezug.
Slackware
"Slackware" (www.slackware.com) ist die älteste noch heute existierende Distribution. Sie verzichtet aus Prinzip auf grafische Einrichtungswerkzeuge und ist daher eher nur für fortgeschrittene BenutzerInnen geeignet.
Bisher nicht vorgekommen sind Distributionen, die nur Abwandlungen anderer Distributionen sind und häufig auch deren Quellen benutzen. Vor allem von Debian gibt es unzählige davon. Sie werden als "Derivate", oder oft auch, etwas abfällig, als "Klone" bezeichnet. Ein solcher "Debian-Klon" hat allerdings Geschichte geschrieben:
Ubuntu
Das von der Firma des Gründers gesponserte kostenlose Betriebssystem soll nach dem Willen der Entwickler ein einfach zu installierendes und leicht zu bedienendes Betriebssystem mit aufeinander abgestimmter Software sein. Es bedient sich dazu aus den Quellen von Debian unstable und hat das Ziel, nach der enormen Popularität zu schließen, eindeutig geschafft.
Tatsächlich kann Ubuntu von der Live-CD mit wenigen Mausklicks problemlos auf die Festplatte installiert werden und dann erwartet den Benutzer ein weitgehend komplettes Betriebssystem mit vielen Multimedia-Programmen. Releases erscheinen mit schöner halbjährlicher Regelmäßigkeit und der Upgrade auf diese lässt sich ebenfalls auf Mausklick bewerkstelligen. Alle 2 Jahre gibt es eine "Versionen mit verlägerter Unterstützung" (Long Term Support oder kurz LTS), die dann deutlich stabiler als die kürzer unterstützten ist. Für EinsteigerInnen ist Ubuntu (www.ubuntu.com) bestens geeignet.
Linux Mint
Diese Distribution war ursprünglich ein Ubuntu-Klon, aber neuerdings ist Linux Mint auch als LMDE - Linux Mint Debian Edition - erhältlich. Den Entwicklern ist es wichtig , die bestmögliche Integration von Programmen zu bieten, die bei Benutzern beliebt, aber eben nicht quelloffene freie Software sind. Die anderen Distribution, inklusive Ubuntu, bieten zwar auch die Installation von "non-free"-Paketen an, aber in einem eigenen Zweig und erst nach der Basisinstallation.
Für absolute Stabilität setzt Linux Mint immer auf LTS (Ubuntu) oder stable (Debian) Versionen auf, aber die integrierten Programme erhalten auch zwischenzeitig Versionsupgrades. Als Vorbild wird die Benutzerfreundlichkeit und Stabilität von Apple's OS X genannt. Auch Linux Mint (www.linuxmint.com) ist für EinsteigerInnen bestens geeignet.
Linux Desktops
Anders als bei Microsoft und Apple gibt es bei Linux-Distributionen keinen festgelegten Desktop. Alle Distributionen bieten die Möglichkeit den Desktop zu ändern und zunehmend kann schon bei der Installation der gewünschte Desktop festgelegt werden. Wenngleich für Anfänger im allgemeinen der Standard-Desktop der jeweiligen Distribution sicher eine gute Wahl ist, möchte ich abschließend auch noch kurz einige Desktops vorstellen.
Gnome vs. KDE
Gnome und KDE sind die Platzhirsche auf Linux-Bildschirmen. Die Frage, welcher Desktop der bessere ist, ist seit je her umstritten und ungeklärt. Beide kommen mit mächtigen Datei-Managern daher und bieten viel Automatisierung. Jeder Versionsupgrade entfacht die Diskussion erneut und, wie auch Windows BenutzerInnen wissen, wird nicht jede Neuentwicklung als Verbesserung empfunden.
XFCE
Während erstgenannte Desktops mit Features protzen gehen die EntwicklerInnen bei XFCE einen anderen Weg. XFCE möchte einen schlanken, performanten Desktop bieten, der auf "unnötige Spielereien" verzichtet und auch auf leistungsschwachen und zum Teil für andere Aufgaben (Multimedia) bestimmten Systemen resourcenschonend läuft. Viele heutige Distributionen bieten XFCE als vorkonfigurierte Alternative zum Standarddesktop an.
MATE und Cinnamon
Der umstrittene Upgrade von Gnome2 auf Gnome3 führte zur Geburt von MATE. Dieser Desktop ist eine direkte Fortentwicklung von Gnome2. Cinnamon dagegen ist aus den Quellen von Gnome3 entstanden, aber deutlich performanter als dieser. Was beide gemeinsam haben - sie sind die Standarddesktops von "Linux Mint" und nur als Ubuntu-Editionen von Linux Mint gibt es auch KDE und XFCE vorkonfiguriert.
Es können auch mehrere Desktops gleichzeitig installiert werden. Bei der Anmeldung kann dann zwischen den Desktops gewechselt werden. So kann jeder seinen Lieblingsdesktop herausfinden.
Soweit zu den theoretischen Grundlagen. Für den folgenden Teil benötigen wir dann schon ein laufendes Betriebssystem mit der Linux-Standardshell BASH.
![]()